Every battery program produces characterization data. XRD on cycled cathodes. Electron microscopy of cross-sections. Impedance spectroscopy at different states of health. Failure-mode autopsies after early-life returns. Most of this data answers diagnostic questions: what is in the cell, where, how much. It tells you what went wrong in a specific cell that already failed.
The data is correct. The use of it is narrow. A defect signature in a microscopy image is treated as a label on the past tense. The cell failed because this happened. The next cell will or will not fail because of whether the same thing happens. The loop is open and the connection between the signature and the failure mechanism is reasoned about rather than observed.
Subatomic computing changes what that data is for.
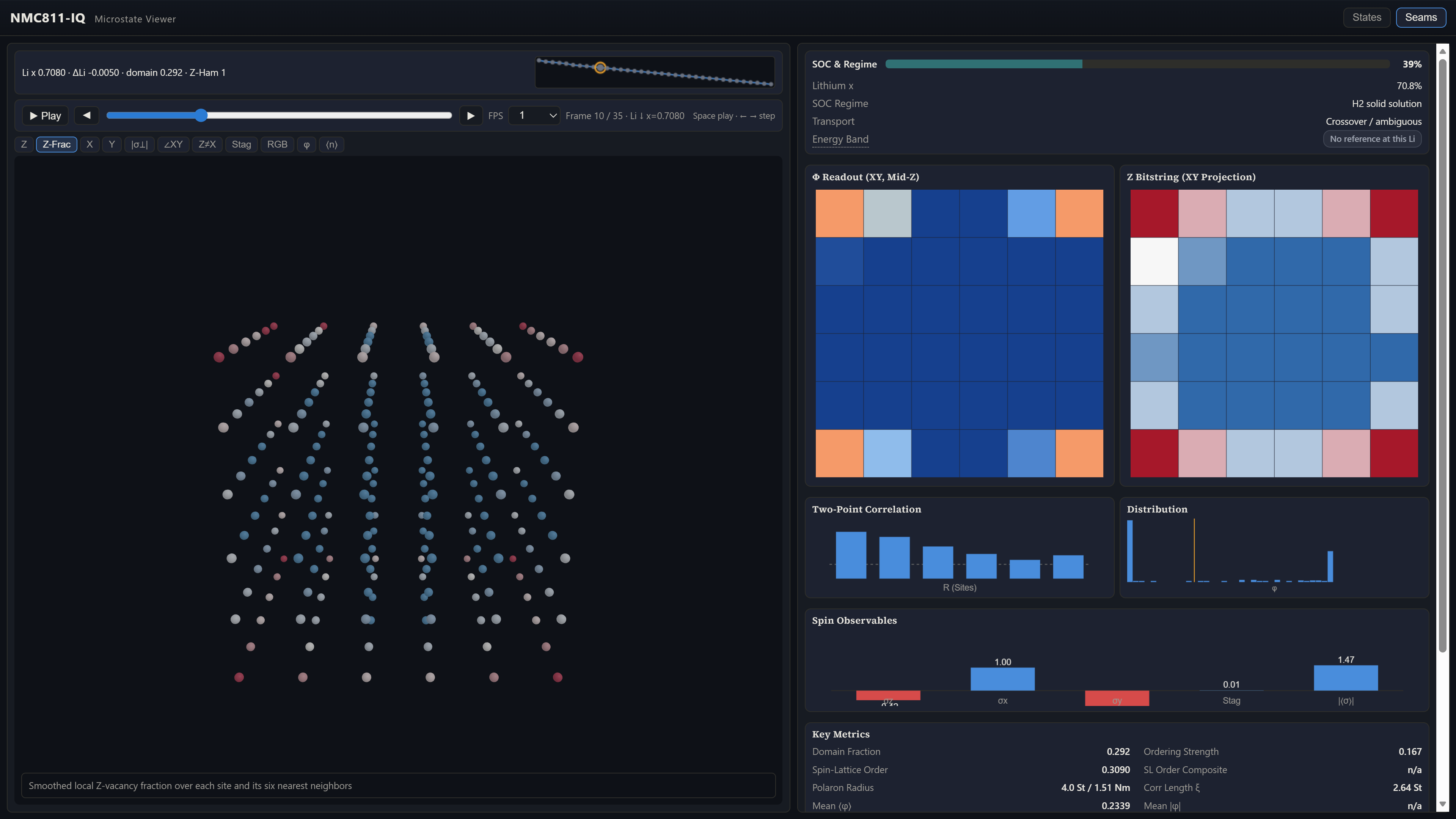
Characterization data becomes a parameter set.
A defect, encoded properly, is a perturbation on a circuit. Not a label on a finished cell. The location of the defect, its geometric extent, its electronic character, and its position relative to the lattice's other features all translate into something the engine can take as input. Once it is in, the engine evolves the system with that perturbation in place and surfaces the microstates the system actually occupies as a consequence.
The same characterization data you already have becomes the parameter set for a study. Not a reference image, not a label. An input. A specification for what the engine should evolve.
The output is the connected evolution of the cell with that defect in it. Every state the system visits across the operating range, validated against physical continuity, available for inspection at quantum resolution. The defect is no longer a static feature in a post-mortem image. It is the seed for a trajectory you can play forward.
Real defects, not generic ones.
The distinction matters. Most simulation work on battery defects uses canonical defect types — oxygen vacancy, transition-metal migration, surface reconstruction — modeled in idealized form. The output is a literature on what these canonical defects do under canonical conditions. Useful, but abstract. The cells you are shipping have specific defect profiles that emerge from your specific manufacturing process, your specific suppliers, your specific operating envelope.
Those specifics matter to outcomes and they matter to decisions. A canonical study tells you what an oxygen vacancy might do. Your characterization data describes what is actually happening in your cells. A study parameterized from your data tells you what your specific configuration does as the system cycles, not what a textbook example does.
The difference is the difference between knowing the general physics of a failure mode and knowing what your cell will do at 87% state of charge with the defect distribution your last production batch produced.
The same logic applies outside batteries. From what the magnet team has shared in our cross-track meetings, they have run an equivalent reframing on magnetic-lattice characterization data — treating measured anisotropy, disorder, and domain structure as inputs to the engine rather than labels on a finished sample. Their limited public release will go through benchmarks.iqintel.io when it is ready. The point holds across material systems: characterization data that has been treated as diagnostic can be treated as input, and what comes out is the forward record rather than the post-mortem.
What comes back from the engagement.
A lab-perfect baseline, run on a clean version of your circuit family, gives you the reference. Multiple defect-profile variants, each derived from your own characterization data, give you the comparison set. Two to four complete cycles for each. Master seams covering the full operating range. The microstate JSON for every state in every cycle, with audit hashes on each record. Dashboard imagery covering ten lattice rendering modes per microstate. Phase diagrams across the engagement.
What this is not: a black box that returns a verdict on your cell. The output is the observable record. Your team reads it. Your team decides what the findings mean for your roadmap.
What this is: a connected, validated, frame-by-frame record of how your cell with your defects moves through state space. The kind of data you cannot collect on a real cell because the instrumentation does not exist, and you cannot compute on arbitrary defect configurations because no one else's engine handles emergence the way ours does.
The bridge from your work to ours.
A research program that has been characterizing its cells well for years already owns the inputs to this kind of study. You do not need to start a new measurement campaign. You do not need to translate your data into a different format that your team no longer recognizes. The defect signatures your microscopists have catalogued, the failure-mode taxonomies your reliability engineers maintain, the operating-envelope choices your cell designers have made — these are exactly the inputs the engine takes.
The engagement is a translation, not a replacement. We do not tell you what your cells are doing wrong. We take what you already know and run it forward, and we hand you back the record of what the system does when your defects are in it.
What you do with that record is your work. It always was.
It does not have to.
The engagement parameterizes a study from what you already own.
Request a confidential discussion